Activation Functions in Neural Networks

What are Activation Functions?
Activation Function of a neuron defines the output of that neuron given a sets of inputs.
They are biologically similar to the activities in our brain, where different neurons are activated by different stimuli.
For example:
A cake will activate some set of neurons (something pleasant) in the brain whereas, a garbage can will activate some other set of neurons (something unpleasant).
Activation Functions are really important for a Artificial Neural Network to learn and make sense of something really complicated and Non-linear complex functional mappings between the inputs and response variable. They introduce non-linear properties to our Network.
Their main purpose is to convert a input signal of a node in a A-NN to an output signal. That output signal now is used as a input in the next layer in the stack.
Is it necessary to have an Activation function?
The answer is YES!
If we do not apply a Activation function then the output signal would simply be a simple linear function. A linear function is just a polynomial of one degree. Now, a linear equation is easy to solve but they are limited in their complexity and have less power to learn complex functional mappings from data.
A Neural Network without Activation function would simply be a Linear regression Model, which has limited power and does not perform good most of the times. Also without activation function our Neural network would not be able to learn and model other complicated kinds of data such as images, videos, audio, speech etc. That is why we use Artificial Neural network techniques such as Deep learning to make sense of something complicated ,high dimensional,non-linear-big datasets, where the model has lots and lots of hidden layers in between and has a very complicated architecture which helps us to make sense and extract knowledge form such complicated big datasets.
Popular Types of Activation Functions:
1. Sigmoid or Logistic
2. Tanh - Hyperbolic tangents
3. ReLu - Rectified Linear Units
1. Sigmoid Function:
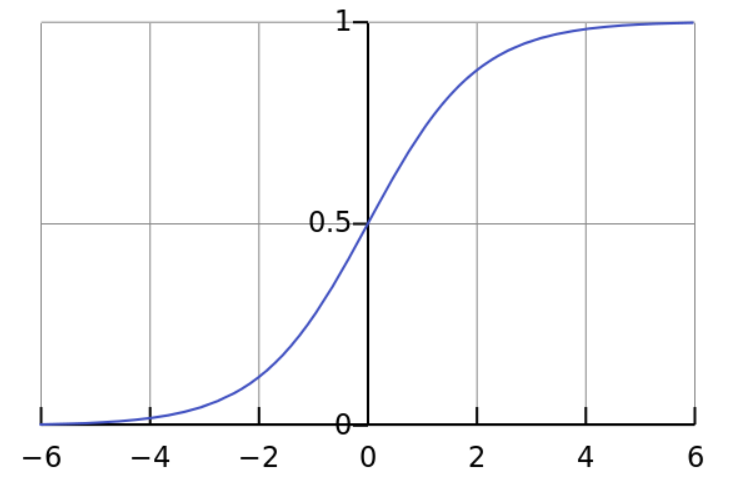

It ranges between 0 and 1.
Here, the values which are negative i.e. less than zero, they are transformed close to zero. Similarly the values which are more than 1 are transformed close to 1.
Issues:
i. Vanishing GradientIf you notice, towards either end of the sigmoid function, the Y values tend to respond very less to changes in X. The gradient at that region is going to be small. It gives rise to a problem of “vanishing gradients”.
Gradient is small or has vanished ( cannot make significant change because of the extremely small value ). The network refuses to learn further or is drastically slow.
ii. Its output isn’t zero centered. It makes the gradient updates go too far in different directions, 0 < output < 1, and it makes optimization harder.
2. Tanh function:

It’s output is zero centered because its range in between -1 to 1 i.e -1 < output < 1 . Hence optimization is easier in this method hence in practice it is always preferred over Sigmoid function.
Issues:
i. Suffers from Vanishing Gradient problem as well.
3. ReLu function:


It gives an output x(input) if x is positive and 0 otherwise.
It avoids and rectifies vanishing gradient problem . Almost all deep learning Models use ReLu nowadays.
Issues:
i. It should only be used within Hidden layers of a Neural Network Model.Hence for output layers we should use a Softmax function for a Classification problem to compute the probabilites for the classes , and for a regression problem it should simply use a linear function.
ii. Another problem with ReLu is that some gradients can be fragile during training and can die. It can cause a weight update which will make it never activate on any data point again, i.e. ReLu could result in Dead Neurons.
To fix this problem another modification was introduced called Leaky ReLu to fix the problem of dying neurons. It introduces a small slope to keep the updates alive.

Which one is better to use?
Nowadays we should use ReLu which should only be applied to the hidden layers. And if your model suffers form dead neurons during training we should use leaky ReLu..
It’s just that Sigmoid and Tanh should not be used nowadays due to the vanishing Gradient Problem which causes a lots of problems to train,degrades the accuracy and performance of a deep Neural Network Model.



Comments
Post a Comment