Recurrent Neural Networks and LSTM explained

What are Recurrent Neural Networks?
Recurrent Neural Networks are the state of the art algorithm for sequential data This is because it is the first algorithm that remembers its input, due to an internal memory, which makes it perfectly suited for Machine Learning problems that involve sequential data.
In simple terms, they are networks with loops in them, allowing information to be saved.

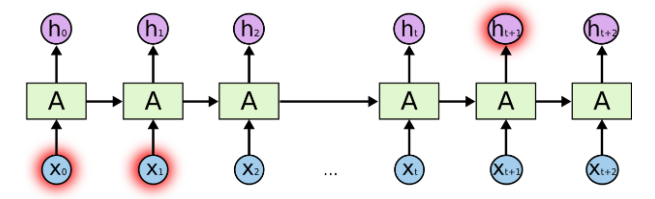
Here, A is the network, Xt is the input with output ht.
Although, these loops makes the RNN kind of hard to interpret, but in reality it is very simple.
This is how the RNN looks when we unroll them.

A RNN can be thought of as multiple copies of the same network , each passing message to
the next.
Because of their internal memory, RNN’s are able to remember important things about the input they received, which enables them to be very precise in predicting what’s coming next.
This is the reason why they are the preferred algorithm for sequential data like time series, speech, text, financial data, audio, video, weather and much more because they can form a much deeper understanding of a sequence and its context, compared to other algorithms.
How Recurrent Neural Network is different from Feed-Forward Neural Network?

RNN’s and Feed-Forward Neural Networks are both named after the way they channel information.
In a Feed-Forward neural network, the information only moves in one direction, from the input layer, through the hidden layers, to the output layer. The information moves straight through the network. Because of that, the information never touches a node twice.
Feed-Forward Neural Networks, have no memory of the input they received previously and are therefore bad in predicting what’s coming next. Because a feedforward network only considers the current input, it has no notion of order in time. They simply can’t remember anything about what happened in the past, except their training.
But in a RNN, the information cycles through a loop. When it makes a decision, it takes into consideration the current input and also what it has learned from the inputs it received previously. Therefore a Recurrent Neural Network has two inputs, the present and the recent past.
The two images above will illustrate the difference in the information flow between a RNN and a Feed-Forward Neural Network.
Issues of standard RNN:
1. "The problem of Long-Term Dependencies"
The main benefit of RNN is that it can connect the past to the present task.
Let's look at this example: "Birds flying in the ."
Here we are trying to predict the next word based on the previous words. We don't need any
other context, as we are pretty sure that the next word is "sky".
In such cases, where the gap/lag between the relevant information and the place where it is needed is small, RNN can easily learn the context using the past information to predict the next word.

But there are some cases, where we need more context. Let's look at the example below:
"I am from France.......(after 3-4 lines)....... I speak fluent ________."
Recent information suggests that the next word is probably the name of a language, i.e. "French". But if we want to narrow down which language, we need the context of France, from further back. It’s entirely possible for the gap/lag between the relevant information and the point where it is needed to become very large.
Here, as the gap/lag increases, RNN is unable to connect the past to the present.
2. Vanishing Gradient
A problem resulting from backpropagation.
This is a problem that involves the earlier weights of the network.

When we have more layers in the network, the gradients with respect to weights in the
earlier layers of the network becomes very small, i.e. it slowly vanishes.
So, what happens is that the gradient is calculated with respect to a particular weight, so the
value is used to update that weight, i.e. the weight gets updated in some way that is
proportional to the gradient. If the gradient is vanishingly small then the update is going to
be vanishingly small as well. So if the new update barely moved from the original value,
then its not really helpful for the network. Hence, the loss would be almost same.
This affect the remainder of the network to the right, and impairs the ability of the network
to learn.
A problem resulting from backpropagation.
This is a problem that involves the earlier weights of the network.

When we have more layers in the network, the gradients with respect to weights in the
earlier layers of the network becomes very small, i.e. it slowly vanishes.
So, what happens is that the gradient is calculated with respect to a particular weight, so the
value is used to update that weight, i.e. the weight gets updated in some way that is
proportional to the gradient. If the gradient is vanishingly small then the update is going to
be vanishingly small as well. So if the new update barely moved from the original value,
then its not really helpful for the network. Hence, the loss would be almost same.
This affect the remainder of the network to the right, and impairs the ability of the network
to learn.
These problems are solved by LSTM's.
LSTM (Long Short Term Memory)
This is a special kind of RNN, capable of learning long term dependencies. Therefore it is well suited to learn from important experiences that have very long time lags in between.LSTM’s enable RNN’s to remember their inputs over a long period of time. This is because LSTM’s contain their information in a memory, that is much like the memory of a computer because the LSTM can read, write and delete information from its memory.
In RNN, the repeating modules will have a simple structure, such as a single tanh layer.

But in LSTM, there are 4 layers, interating in a very special way.


This memory can be seen as a gated cell, where gated means that the cell decides whether or not to store or delete information (e.g if it opens the gates or not), based on the importance it assigns to the information. The assigning of importance happens through weights, which are also learned by the algorithm. This simply means that it learns over time which information is important and which not.
In an LSTM there are three gates: input, forget and output gate. These gates determine whether or not to let new input in (input gate), delete the information because it isn’t important (forget gate) or to let it impact the output at the current time step (output gate).

The gates in a LSTM are analog, meaning that they range from 0 to 1. The fact that they are analog, enables them to do backpropagation with it.


Comments
Post a Comment