Convolutional Neural Network Explained

What are Convolutional Neural Networks?
Convolutional neural network (CNN, or ConvNet) is a class of deep, feed-forward artificial neural networks that has successfully been applied to analyzing visual imagery.
ConvNets have been successful in identifying faces, objects and traffic signs apart from powering vision in robots and self driving cars.
The working of a CNN is very simple. We have an input image that goes into the convolutional neural network and then we get the output in the form of class labels.


The CNN works on the features of each image. After training it is able to give probabilities of each target class, i.e. say 80% happy or 90% sad.
How does a neural network able to recognize the features?
Lets say we have a black & white image of 2x2 pixel. Now in computer terms, this b/w image is a 2D array. That is what the machine uses to learn from images.

Now, lets say we have a colored image of 2x2 pixel. In this case, it is a 3D array. We have a red, green and a blue layer (RGB).

There are 5 main operations in the CNN:
- Convolution
- Non Linearity (ReLU)
- Pooling
- Flattening
- Fully Connected Layer
Initially, every Image is represented as a matrix of pixel values.

Step 1: Convolution
The primary purpose of this step is to extract important features from the image and make the image smaller.

Then the Convolution of the original image and the filter is calculated and we get a new matrix called the Feature map. They help us to maintain the important things in the image and ignore the unnecessary parts.
NOTE: There are many types of filters/feature detectors, such as edge detection, sharpen, blur etc etc. And each of them have a unique matrix and they give us different feature maps.

Problem: If we use only 1 feature map, then there will be loss of information. As only 1 type of informations are taken into account.
So, to cure this problem we use many different feature maps to obtain our first Convolutional layer. Different filters are applied that creates different feature maps and through its training they decide which features are important to categorize the images.

Step 2: Non-linearity (ReLU)
An additional operation called ReLU is used after every convolution operation.
ReLU stands for Rectified Linear Unit and is a non-linear operation. It is applied to increase the non-linearity in our CNN.

ReLU is an element wise operation which is applied per pixel and replaces all negative pixel values in the feature map by zero. The main purpose is to introduce non-linearity in our CNN, since most of the real world application that we want our CNN to learn would be non-linear.
NOTE: Convolution is linear operation: element wise matrix multiplication and addition.
So, to account for non-linearity we use ReLU.

From the image above, we applied ReLU to a feature map which had positive and negative values. As an output we got the Rectified feature map which has only non-negative values in it.
That is, when we take out the black (negative values), we break the linearity.
Other non-linear functions: tanh and sigmoid
Step 3: Pooling
The purpose of this step is to reduce the dimensionality of each feature map by retaining the most important features.
There are different types of pooling: Max, Average, Sum etc
In max-pooling we take the largest elements from the rectified feature map within that window, In average-pooling, we take the average of all elements and in sum-pooling, we take the sum of all elements from the rectified feature map.
example:


In above figure, we applied max-pooling operation where we take the largest element in the 2x2 window and place it in the pooled feature map.
NOTE: we apply pooling to each feature maps separately.

- reduces the size of the input features, which results in faster processing.
- also reduces the number of parameters, preventing overfitting.- retains the important features.
Step 4: Flattening
The purpose of this is to flatten the pooled feature maps into a sequencial column one after the other.
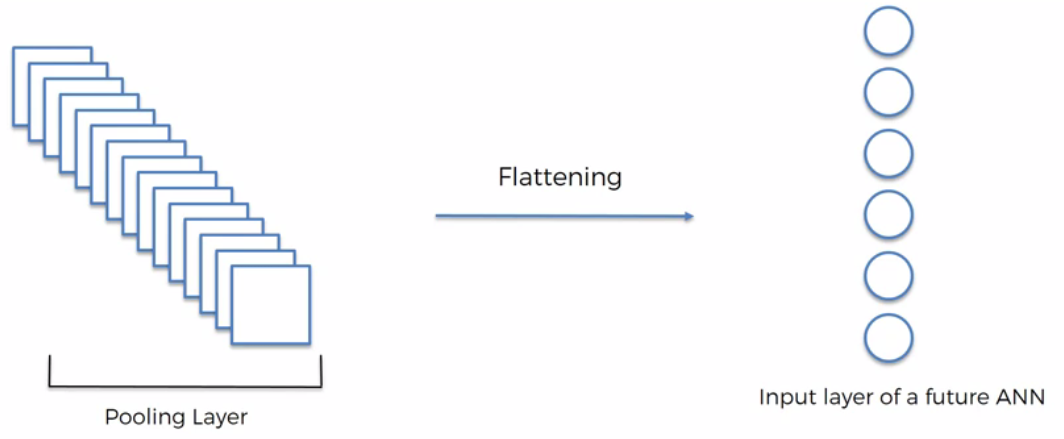
This sequencial column is one huge vector of inputs for the artificial neural network.
so far...

Step 5: Full Connection
In the previous step we got a vector of inputs for the artificial neural network. Now, the purpose of the fully connected layer is to take these inputs/features for classification into different classes.

The fully connected layer calculates the probability of the input image and the image is classified accordingly.
The sum of output probabilities from the Fully Connected Layer is 1. This is ensured by using Softmax as the activation function in the output layer of the Fully Connected Layer. The Softmax function takes a vector of arbitrary real-valued scores and squashes it to a vector of values between zero and one that sum to one.
Uses Backpropagation to calculate the gradients of the error with respect to all weights in the network and gradient descent to update all filter values / weights and parameter values to minimize the output error.



Comments
Post a Comment