Machine Learning Project 3 - Credit Card Fraud Detection

Aim:
The goal of this project is to automatically identify fraudulent credit card transactions using Machine Learning.
This is a binary classification problem.
My approach is explained below:
Workflow:
1. Check the distribution of the classes in the response variable - whether it is an imbalanced or a balanced dataset.
2. Create a baseline model (LogisticRegression), and check recall value for fraudulent transaction class:
a. if low recall value, then solve for the imbalanced data.
i. Under-sampling
ii. Over-sampling methods.
b. if high recall value, move forward.
3. Model Selection: train with other models and select the best one.
4. Feature Selection: apply feature selection techniques to select the best features.
4. Feature Selection: apply feature selection techniques to select the best features.
5. Final model
Model Evaluation methods:
1. Recall Values
2. Precison Values
3. Area under curve
2. Precison Values
3. Area under curve
1. Class Distribution:

This is an imbalanced dataset. There are total 2,84,807 number of transaction details, out of which 284315 are legal transactions and only 492 (i.e. 0.17%) transactions are fraudulent.
2. Baseline Model: Logistic Regression
The dataset is divided into training and validation sets with 70:30 ratio.

The baseline model predicts the non-fraudulent class perfectly but predicts only 62% of the fraudulent class correctly. This is too low, i.e. 38% of the fraudulent transactions are predicted as non-fraudulent.
This is due to the imbalance in the distribution of the response variable.
Lets solve this Imbalanced problem:
i. Random Under-sampling:
Random Undersampling aims to balance class distribution by randomly eliminating
majority class transactions. This is done until the majority and minority class instances are balanced out.
In this case we are taking 10% training samples without replacement from Non-Fraud transactions.
i.e.
Number of Non-Fraudulent transactions : 199019
Number of Fraudulent transactions : 345
So, 10% of Non-Fraudulent transactions = 19902


As you can see, recall value for fraudulent transactions increased from 62% to 80%, which is a massive jump. Also, the model maintained the precision value above 80% as well.
ii. Random Over-sampling:
Over-Sampling increases the number of instances in the minority class by randomly replicating them in order to present a higher representation of the minority class in the sample.
So, in this case our number of minority class transactions will be (345 * 10) = 3450


We are getting a slightly better results in over-sampling. Random over-sampler predicted a total of 3 correct predictions more than under-sampler.
Both the models have pretty much the same area under curve, but since Random over-sampler predicted 3 transactions correctly more than the other, lets go forward with that.
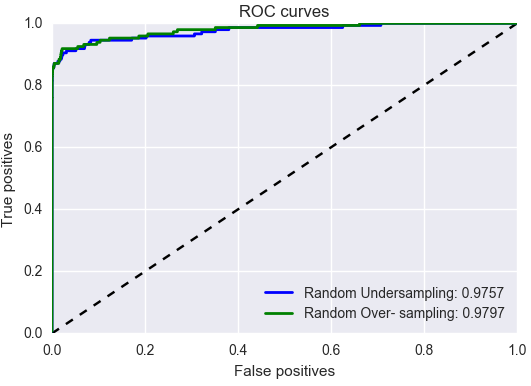
NOTE: SMOTE AND ADASYN are other types of Over-sampling techniques, which were tried out but could not go past Random Over-sampling.
3. Model Selection:
The following models were tried with Over-sampled data:
1. Logistic Regression
2. Stochastic Gradient Descent
3. Random Forest
4. Gradient Boosting
5. XGBoost
The best performing model is: LogisticRegression and XGBoost
Both models have similar performance.
 Moving forward, I will take both these models and apply some Feature Selection techniques.
Moving forward, I will take both these models and apply some Feature Selection techniques.
4. Feature Selection:
The following techniques were tried with LogisticRegression and XGBoost:
1. Recursive Feature Elimination
2. Weights based selection
3. Variance threshold
The best performing technique: Recursive Feature Elimination with XGBoost model
Number of Original Features = 29
Number of Selected Features = 14

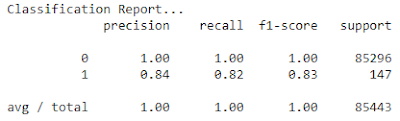 With Recursive Feature Elimination(RFE), XGBoost is performing a little bit better, as it is predicting 4 more transactions correctly.
With Recursive Feature Elimination(RFE), XGBoost is performing a little bit better, as it is predicting 4 more transactions correctly.

The following models were tried with Over-sampled data:
1. Logistic Regression
2. Stochastic Gradient Descent
3. Random Forest
4. Gradient Boosting
5. XGBoost
The best performing model is: LogisticRegression and XGBoost
Both models have similar performance.

4. Feature Selection:
The following techniques were tried with LogisticRegression and XGBoost:
1. Recursive Feature Elimination
2. Weights based selection
3. Variance threshold
The best performing technique: Recursive Feature Elimination with XGBoost model
Number of Original Features = 29
Number of Selected Features = 14



5. Final Model:
"XGBoost with Recursive Feature Elimination"
Mean Cross_validation score: 99.83%
Validation accuracy : 99.92%
Validation RMSE : 0.028
To view the full code for this project in Github, Click Here



This is good stuff man!!
ReplyDeletehelped me.. :)
keep up the great work.